
TOWARDS A DATA UNIVERSE
Data isn't oil any more
Data, it has been said, is the new oil. A precious resource, extracted through mining to power industry. When Clive Humby made this observation a full 18 years ago, he wasn’t wrong. He meant that data, much like fossil fuels, needed to be refined and processed to deliver its true value.
Too cheap to bill for
Five years before Humby, Gartner’s Doug Laney laid out the three Vs of data: Volume, Variety, and Velocity. His point was that these three attributes of information are in direct opposition: If you want to analyze a lot of varied data quickly, it’s going to cost you.
For much of the twenty-first century, engineers have crushed that cost. A modern search engine borders on omniscience, combining all of human knowledge with image detection, realtime mapping, and many more features we take for granted—and yet it’s too cheap to charge for. Distributed computing, algorithmic advances and faster hardware gave us a device in our pocket that makes James Bond’s gadgets laughably quaint.
The dividends of Big tech
Many of the innovations in Big Data came from the consumer Internet. LinkedIn launched in 2002, Facebook in 2004, Twitter in 2006—all of them analyzing millions of data points to build graph databases. Google’s developers figured out how to split a task into tiny parts, farm them out to hundreds of machines, and reassemble the result in the time it takes to serve an ad. Algorithms learned to predict our sentences, our viewing preferences, and our friends.
The early years of computing belonged to governments—who commissioned the first mainframes to run the census—and the military, running simulations of atomic explosions and calculating missile trajectories. Corporations soon embraced these tools, turning filing cabinets and ledgers into columns and rows.
But enterprises and governments were slow to adopt consumer technologies, and for years, corporate systems lagged behind the tools people used at home. Only recently have the benefits of mobility, collaboration, and realtime communication become impossible for large corporations to ignore.
Homo Connectus
Computing and data have transformed us. We haven’t noticed, because we’ve been part of that transformation, but two decades into the Big Data revolution, humanity is a different creature. Billions of us spend roughly a third of our lives in an online realm that is fundamentally different from the one in which our species evolved. It is a world built not of atoms, but of bits—and one in which the usual rules do not apply. Consider the following differences:
Then and Now
| Points of differences | Digital things made of bits | Physical things made of atoms |
|---|---|---|
| Cost to create |
Zero (nearly.)
|
Non-zero (even for commodities.)
|
| Uniqueness |
Copies indistinguishable from the original.
|
Copies are imperfect.
|
| Friction/cost to move |
Vanishingly small (massless.)
|
Significant (has mass.)
|
| Speed of movement |
Instantaneous (light speed.)
|
Slow (physical limits, friction.)
|
| Permanence |
Impermanent (disappears unless we supply energy.)
|
Permanent (takes energy to destroy.)
|
A simple consequence of these different laws is the rise of multiplayer software. We no longer work on a thing in isolation; we share a link, and others hear a song. We type a sentence, and others see their documents change. Adobe bought Figma for $20B because it couldn’t create a multiplayer design platform—it had to buy one that was built from the ground up for the new realities of the modern Internet.
The inhabitants of this online world are indeed different creatures. We have the sum of human knowledge in our pockets. We’re seldom more than a tap away from everyone we know. Our interests, not our geography, dictate with whom we spend time. We have the freedom to work from anywhere—and the mandate to do so around the clock. Devices track our food, our sleep, and our genes; algorithms choose who we date and who we hate. Much of humanity is now Homo Connectus, a new species finding its feet in a digital, data-driven reality.
In 1922, a Jesuit Priest named Pierre Teilhard de Chardin proposed the concept of the Noosphere. To de Chardin and his contemporaries, this “third realm” is the natural successor to the physical world and the biosphere. It is made up of the interaction of human minds. Fast forward to 1967, and British Philosopher Sir Karl Popper introduced the concept of “World 3”, the objective content of thoughts, corresponding to humanity’s knowledge and culture.
By now, it’s clear that technology has connected us into a digital superorganism, built atop bits rather than atoms. Perhaps an updated metaphor for data is blood. Blood, like data, circulates constantly, carrying both pathogens and antibodies. Our organs clean it and regenerate it. It’s rich in information—the average human has 25 trillion blood cells, each containing a copy of our DNA. Data is not the new oil—it is the lifeblood of our new species.
The computing pendulum
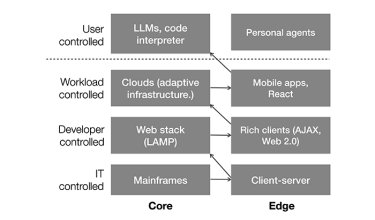
Talk of superorganisms might seem fanciful, so let’s take a step back and look at the history of enterprise computing in these fifty years to understand how we got here: The pendulum of technology.
IT swings on a pendulum between centralization and edge computing, often driven by bottlenecks in networking, processing, and storage.
IT-controlled core computing: In the early days of the computer revolution, computing was precious and tightly controlled by the IT team. Academics carried stacks of punched cards to the mainframe in the middle of the night, because computing was expensive and humans were cheap. Eventually, dumb terminals made it easier to access mainframes and minicomputers, but the power was still at the core of the network.
IT-controlled edge computing: As network performance improved, we adopted client-server architectures. Relatively powerful PCs handled the user interface and computing, talking across the Local Area Network using protocols like Token Ring, Vines, NetBIOS, and Banyan Vines.
Developer-controlled core computing: With the dawn of the Internet, a common data stack appeared: Linux, Apache, MySQL, and PHP. The web browser was dumb, simply rendering HTML; the web server did all the work. With these open source projects widely available in data centers around the world, the developers, rather than IT, controlled compute resources.
Developer-controlled edge computing: The architecture soon swung back to the edge. Browsers added features, from the ability to display images to the ability to run plugins like Java and Flash, to Javascript and WebSockets. In 2005, Jesse James Garrett coined the term APEX (Asynchronous JavaScript and XML) to describe a set of web development techniques that allowed web pages to update asynchronously by exchanging data with a web server behind the scenes—reloading parts of a web page constantly, making apps like GMail and Google Maps interactive.
Workload-controlled core computing: With cloud computing the pendulum swung once again to the core. Elastic compute meant that the workload itself could add resources as needed, spinning up additional storage, network, and processing.
Workload-controlled edge computing: Consumer electronics have since become incredibly powerful. A 2016 Apple Watch has the same computing power as a Cray 2 Supercomputer from the eighties, meaning that phones, tablets, and even watches can do more of the heavy lifting. Protocols like AirDrop, Bluetooth and Thread run Personal Area Networks that coordinate home devices, and can even farm out computing tasks across the considerable power in our home devices.
The following diagram illustrates this pendulum, showing how IT, then developers, and finally workloads themselves decided how and where to allocate resources:

But the pendulum is swinging once again.
User-controlled core computing: Generative AI and Large Language Models, trained on trillions of parameters at a cost of millions of dollars, can reason, translate, and illustrate better than many humans. While nascent, they represent an entirely new form of nondeterministic computing—and with it, an entirely new software stack. One of the most disruptive attributes of nondeterministic computing is that it can write deterministic software: ChatGPT’s Advanced Data Analysis lets anyone create Python code that will analyze data—even if the user has no programming knowledge—and run it. We are now in the era of user-controlled workloads.
User-controlled edge computing: What happens when the pendulum swings back to the edge is anyone’s guess. By democratizing the creation of applications, generative AI turns everyone into a developer, spinning up ephemeral, single-purpose micro-applications to complete a task, then vanish. We’re moving towards a world of personal agents, where human-machine chimera work and live in tandem.
A Data Universe
It’s time for a new kind of discussion about the role of data in business and society. Data feeds our algorithms. It records our collective knowledge. It gives us the feedback to adapt to a rapidly changing world. It is as vital as blood.
Our data-driven future also demands great care. The more we depend on it, the more resilient and secure the systems on which it relies must be. The more we trust it, the more thoughtful our ethics governance must become. The more we let it predict our future, the more we must understand the mistakes in our past
Much of the data universe remains unwritten, but one thing is certain: As the constraints of atoms give way to the possibilities of bits, turning data into outcomes is critical not only for business, but for humanity itself. This isn’t just about infrastructure, or business intelligence, or resiliency, or innovation—it’s about the society we’re building as a connected species, and the flow of data that powers it.
That’s why we’re gathering experts from technology, business, and academia in New York in April, 2024 for the inaugural Data Universe event. Across five stages and sixteen tracks, we’ll explore every facet of the data revolution.
Stage: Engineering and Infrastructure
The foundational platforms and technologies on which data-driven, AI-enabled businesses operate, and how to keep them running fast and flawlessly.
They call it Big Data for a reason. Powerful processing, high-bandwidth networking, and massive storage—along with the teams who design, deploy, and automate those platforms—underpin any data strategy.
- Data Engineering is an entirely new profession that combines product development, operations, model maintenance, realtime and batch processing, and more, borrowing from DevOps and architecture.
- Large-scale data lakes and data warehouses store petabytes of unstructured and structured data, while streaming platforms deliver thousands of data points every second that must be analyzed and categorized in real time. Ensuring these systems scale and perform under load is critical.
- The best systems in the world can’t help if they’re offline. Data platforms must, above all, be reliable, which means maintaining backups, red-teaming disasters, and maintaining careful plans for recovery to deliver maximum uptime and resiliency.
- The modern Data Stack consists of hardware, software, and tools, all working in concert to turn raw data into business advantage.
Stage: Analytics and Intelligence
The tools and techniques that turn raw data into vital insights, letting you explore information, convince others, and decide better.
Data is not knowledge. It takes insights to convert raw information into understandings you can act on, unearthing novel connections and discerning unexpected patterns, applying the latest methods and technologies to the analysis of data.
- The first step in any business decision is analytics—the discovery of changes or patterns within data, using statistics, visualization and comparisons to set baselines, identify changes, and unearth new insights.
- Beyond simple analytics lies decision intelligence, making data-informed business decisions to choose the next best action and create stories that compel action. Companies that decide with data instead of intuition have 5%-6% higher productivity and profits than competitors.
- While generative AI has taken the world by storm in recent months, machine learning has long been used to extract meaning from data. From expert systems that help navigate complex, multi-factor decisions to automatic classification to prediction, applied AI is already a competitive must-have.
Stage: Governance, Privacy and Security
How to protect your organization, your users, and your data in an ever-changing legal landscape.
With great power comes great responsibility—and there are few technologies as powerful as Data Science and AI. The executives, lawyers, and risk officers tasked with safeguarding the organization and its customers face an entirely new landscape.
- Data is heavily regulated, and while the Internet knows no borders, companies must navigate complex legal jurisdictions or face significant, sometimes calamitous, penalties. Given the rapid pace of technological advancement, governance and compliance are a constant challenge and a moving target.
- Sharing data among partners to reap its full potential while keeping personal information private makes ensuring data privacy mandatory—and hard.
- We’ve already seen how valuable data is—so attackers are more motivated than ever to steal it or ransom an organization for its return. Big Data and AI present new attack surfaces, and generative AI can create novel zero-day exploits that evade traditional protections. Information security is more than just stopping hackers, it’s guarding your most precious resource.
Stage: Business Strategy and Transformation
Navigating the game-changing possibilities of big data and AI, so you can build a team, draft a business case, and execute competitive strategies to reshape an industry in your favour.
Data science and AI are powerful new tools, but they only matter if you can fundamentally alter the value your business creates in a sustainable, repeatable way. How do the best organizations transform their businesses and reinvent their industries?
- A strategy is simply a plan for how to win. And with data, the game has changed, creating entirely new strategies. To succeed, you need a clear vision of the outcomes you’re after, based on what’s now possible. Then you need to get buy-in and funding for your data strategy.
- What’s now possible—and what’s obsolete? Business reinvention means changing the way your organization functions, competing differently, and disrupting how your customers perceive value creation.
- To make the most of the data opportunity, you need the right team, and that means hiring, retaining, upskilling, and even rightsizing, your team. A data-driven world means different teams and talent.
Stage: Emerging Tech, Society, and Ethics
Cutting-edge startups, groundbreaking science, and how to mitigate the unintended consequences of innovation while keeping humanity and ethics at the core of progress.
While much of Data Science and AI is widely applied today, there remain vast opportunities for innovation. On the Emerging Tech, Society and Ethics stage we look at what we might build—and whether we should. While there’s already plenty to tackle that’s in production today, we’d be remiss if we didn’t spend time on what the future might hold, and what that means for humanity.
- A few short years ago, we were in an AI Winter. But the launch of widely available generative AI, from GPT to Stable Diffusion and beyond, revitalized the field; now businesses around the world are clamoring to deploy it.
- Technology moves fast, and while we’re still building out our data and AI stacks, new tools are rapidly approaching. Distributed, decentralized data models help organizations that don’t trust one another coordinate their activity; augmented environments create new layers of data atop the physical world; quantum processors make some of computing’s hardest tasks trivial.
- Few people worried about the impact of the mainframe on humanity. Even the personal computer was, at its inception, a niche product. But now that billions of humans spend a third of their lives online, it’s clear that technology isn’t agnostic, and we need ethical algorithms. If we get this wrong, we’ll undermine fairness, employment, democracy, and the nature of truth itself.
The data universe is manifold, packed with vital topics at the forefront of modern society. Whether you’re a practitioner who wants to hone your skills and connect with peers, a business leader seeking deeper a understanding of where data is headed and who’s leading change, an executive itching to separate hype from actionable reality, or an innovator eager to find investors and customers, it’s clear that data is the lifeblood of an online world. As the IT pendulum swings inexorably towards use-controlled computing and a second IT stack, it’s time to act.