
Building the Second Stack

We are in the Great Acceleration – a singularity, not in the capital-S-Kurzweilian sense of robots rising up, but in the one Foucault described: A period of time in which change is so widespread, and so fundamental, that one cannot properly discern what the other side of that change will be like.
We’ve gone through singularities before:
- The rise of agriculture (which created surplus resources and gave us the academic and mercantile classes).
- The invention of the printing press (which democratized knowledge and made it less malleable, giving us the idea of a source of truth beyond our own senses).
- The steam engine (which let machines perform physical tasks).
- Computer software (which let us give machines instructions to follow).
- The internet and smartphones (which connect us all to one another interactively).
This singularity is, in its simplest form, that we have invented a new kind of software.
The Old Kind of Software
The old kind of software – the one currently on your phones and computers – has changed our lives in ways that would make them almost unrecognizable to someone from the 1970s. Humanity had 50 years to adapt to software because it started slowly with academics, then hobbyists, with dial-up modems and corporate email. But even with half a century to adjust, our civilization is struggling to deal with its consequences.
The software you’re familiar with today – the stuff that sends messages, or adds up numbers, or books something in a calendar, or even powers a video call – is deterministic. That means it does what you expect. When the result is unexpected, that’s called a bug.
From Deterministic Software to AI
Earlier examples of “thinking machines” included cybernetics (feedback loops like autopilots) and expert systems (decision trees for doctors). But these were still predictable and understandable. They just followed a lot of rules.
In the 1980s, we tried a different approach. We structured software to behave like the brain, giving it “neurons.” And then we let it configure itself based on examples. In 1980, a young researcher named Yann LeCun tried this on image classification.
He’s now the head of AI at Meta.
Then AI went into a sort of hibernation. Progress was being made, but it was slow and happened in the halls of academia. Deep learning, TensorFlow and other technologies emerged, mostly to power search engines, recommendations and advertising. But AI was a thing that happened behind the scenes, in ad services, maps and voice recognition.
In 2017, some researchers published a seminal paper called, “Attention is all you need.” At the time, the authors worked at Google, but many have since moved to companies like OpenAI. The paper described a much simpler way to let software configure itself by paying attention to the parts of language that mattered the most.
An early use for this was translation. If you feed an algorithm enough English and French text, it can figure out how to translate from one to another by understanding the relationships between the words of each language. But the basic approach allowed us to train software on text scraped from the internet.
From there, progress was pretty rapid. In 2021, we figured out how to create an “instruct model” that used a process called Supervised Fine Tuning (SFT) to make the conversational AI follow instructions. In 2022, we had humans grade the responses to our instructions (called Modified Supervised Fine Tuning), and in late 2022, we added something called Reinforcement Learning on Human Feedback, which gave us GPT-3.5 and ChatGPT. AIs can now give other AIs feedback.
Whatever the case, by 2024, humans are the input on which things are trained, and provide the feedback on output quality that is used to improve it.
When Unexpected is a Feature, Not a Bug
The result is a new kind of software. To make it work, we first gather up reams of data and use it to train a massive mathematical model. Then, we enter a prompt into the model and it predicts the response we want (many people don’t realize that once an AI is trained, the same input gives the same output – the one it thinks is “best” – every time). But we want creativity, so we add a perturbation, called temperature, which tells the AI how much randomness to inject into its responses.
We cannot predict what the model will do beforehand. And we intentionally introduce randomness to get varying responses each time. The whole point of this new software is to be unpredictable. To be nondeterministic. It does unexpected things.
In the past, you put something into the application and it followed a set of instructions that humans wrote and an expected result emerged. Now, you put something into an AI and it follows a set of instructions that it wrote, and an unexpected result emerges on the other side. And the unexpected result isn’t a bug, it’s a feature.
Incredibly Rapid Adoption
We’re adopting this second kind of software far more quickly than the first, for several reasons:
- It makes its own user manual: While we’re all excited about how good the results are, we often overlook how well it can respond to simple inputs. This is the first software with no learning curve – it will literally tell anyone who can type or speak how to use it. It is the first software that creates its own documentation.
- Everyone can try it: Thanks to ubiquitous connectivity through mobile phones and broadband, and the SaaS model of hosted software, many people have access. You no longer need to buy and install software. Anyone with a browser can try it.
- Hardware is everywhere: GPUs from gaming, Apple’s M-series chips and cloud computing make immense computing resources trivially easy to deploy.
- Costs dropped. A lot: Some algorithmic advances have lowered the cost of AI by multiple orders of magnitude. The cost of classifying a billion images dropped from $10,000 in 2021 to $0.03 in 2023 – a rate of 450 times cheaper per day.
- We live online: Humans are online an average of six hours a day, and much of that interaction (email, chatrooms, texting, blogging) is text-based. In the online world, a human is largely indistinguishable from an algorithm, so there have been many easy ways to connect AI output to the feeds and screens that people consume. COVID-19 accelerated remote work, and with it, the insinuation of text and algorithms into our lives.
What Nondeterministic Software Can Do
Nondeterministic software can do many things, some of which we’re only now starting to realize.
- It is generative. It can create new things. We’re seeing this in images (Stable Diffusion, Dall-e) and music (Google MusicLM) and even finance, genomics and resource detection. But the place that’s getting the most widespread attention is in chatbots like those from OpenAI, Google, Perplexity and others.
- It’s good at creativity but it makes stuff up. That means we’re giving it the “fun” jobs like art and prose and music for which there is no “right answer.” It also means a flood of misinformation and an epistemic crisis for humanity.
- It still needs a lot of human input to filter the output into something usable. In fact, many of the steps in producing a conversational AI involve humans giving it examples of good responses, or rating the responses it gives.
- Because it is often wrong, we need to be able to blame someone. The human who decides what to do with its output is liable for the consequences.
- It can reason in ways we didn’t think it should be able to. We don’t understand why this is.
The Pendulum and Democratization of IT
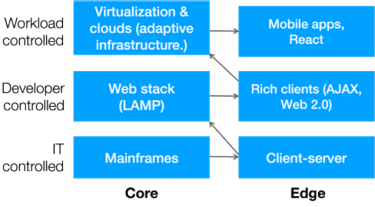
While, by definition, it’s hard to predict the other side of a singularity, we can make some educated guesses about how information technology (IT) will change. The IT industry has undergone two big shifts over the last century:
- A constant pendulum, it’s been swinging from the centralization of mainframes to the distributed nature of web clients.
- It’s a gradual democratization of resources, from the days when computing was rare, precious and guarded by IT to an era when the developers, and then the workloads themselves, could deploy resources as needed.
This diagram shows that shift:
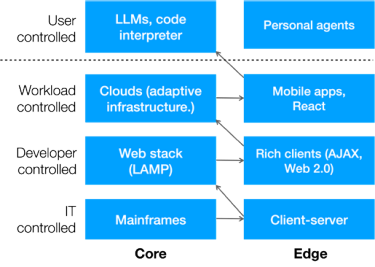
There’s another layer happening thanks to AI: User-controlled computing. We’re already seeing no-code and low-code tools such as Unqork, Bubble, Webflow, Zapier and others making it easier for users to create apps, but what’s far more interesting is when a user’s AI prompt launches code. We see this in OpenAI’s ChatGPT code interpreter, which will write and then run apps to process data.
It’s likely that there will be another pendulum swing to the edge in coming years as companies like Apple enter the fray (who have built hefty AI processing into their homegrown chipsets in anticipation of this day). Here’s what the next layer of computing looks like:
Building a Second Stack
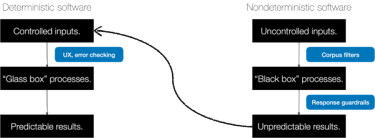
Another prediction we can make about IT in the nondeterministic age is that companies will have two stacks.
- One will be deterministic, running predictable tasks.
- One will be nondeterministic, generating unexpected results.
Perhaps most interestingly, the second (nondeterministic) stack will be able to write code that the first (deterministic) stack can run – soon, better than humans can.
The coming decade will see a rush to build second stacks across every organization. Every company will be judged on the value of its corpus, the proprietary information and real-time updates it uses to squeeze the best results from its AI. Each stack will have different hardware requirements, architectures, governance, user interfaces and cost structures.
We can’t predict how AI will reshape humanity. But we can make educated guesses at how it will change enterprise IT, and those who adapt quickly will be best poised to take advantage of what comes afterwards.
MEET THE AUTHOR AT DATA UNIVERSE
Alistair Croll is author of several books on technology, business, and society, including the bestselling Lean Analytics. He is the founder and co-chair of FWD50, the world's leading conference on public sector innovation, and has served as a visiting executive at Harvard Business School, where he helped create the curriculum for Data Science and Critical Thinking. He is the conference chair of Data Universe 2024.
Want Weekly Insights delivered straight to your inbox?
Sign up below to make sure you never miss out on the newest stories from Data Universe.